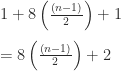I’ve wanted to “be a programmer” for several years now but until recently I haven’t been committed enough to actually learn. I took some computer science courses but they were mostly from the hardware side, very fun though.
And, then, there was always other things to do.
Within the last month or so though I’ve been working on teaching myself python. I first fraternized with python when using the graphics library matplotlib for my QSO project. I struggled with making a contour plot using the library which shamed me into finally making an effort to learn how to tell my computer to do fancy tricks.
I’ve been doing fine with the most basic of basic stuff. Read in a file, sum an array, guess a random number, on and on…I didn’t really need to pause and think hard about what I was doing until I started getting into sorting algorithms.
It’s a very basic task. Take a list of names and put them in alphabetical order. So easy that I’ll eat pie as I do it. I decided to start off with an extra helping of challenge so I didn’t look up any sorting algorithms. I have never taken a computer science class, I was unsullied, I didn’t know what the common algorithms for sorting an unordered list are. It ended up being a difficult thing for me to get my head around (which is a difficult thing to admit since it seems like simple so I might delete this sentence later).
I gravitated to the idea of creating a new array that I would sort the names into which, from speaking to Joe, I learned is a common algorithm. But I just couldn’t get it to work. I struggled with getting the right compares to happen, then when I did get the elements compared properly I was at a loss on how to get the program to do the right thing with the elements to sort them. This is what I ended up with, it works but it’s completely not my idea,,
names=["Zooey","Joe","Ashela","Alexa","Walder","Adrianna"]
sorted_array=[]
x=0
while x < len(names):
i=0
while i < len(sorted_array) and names[x] > sorted_array[i]:
i=i+1
sorted_array.insert(i,names[x])
x=x+1
print names
print sorted_array
The biggest insight I got from this was while loops are more than just things used to count. At my work at Gemini I only ever use while loops to keep track of lists of files. I thought I knew them well but my eyes are open now. In this example I’m using the inner while loop to keep track of two conditions; that ‘i’ is staying within the bounds of sorted_array and what position names[x] should be put in. A name gets pulled out of the unsorted array and is compared to what’s already in the sorted array. Whenever names[x] comes after something that’s already sorted we push ‘i’ up until the second condition of the inner loop is not fulfilled, then ‘i’ marks the spot.
The only point I get on this was is that I was able to properly come up with the concept of “insert sort” but I sadly lacked the skills to actually come up with a correct algorithm and program it.
So I decided to try again with bubble sort.
Joe told me about the concept and I went for it in the hopes of regaining my honor. At first I came up with a seemingly correct but, on close inspection, clearly wrong algorithm. I did eventually get it right but let’s start with the specious example,
names=["Zooey","Joe","Ashela","Alexa","Walder","Adrianna"]
x=0
while x < len(names):
for i in range(0,len(names)-1-x):
print names[x], names[i]
if names[i] > names[i+1]:
names[i],names[i+1]=names[i+1],names[i]
x+=1
print names
“Bubble sort” gets it’s name because the sorted words are supposed to “bubble” up. Basically, if you compare and swap enough times you’ll get to a point where you don’t have to swap anymore. If you look at this for about 1 second (which is about the amount of thought I put into it) the above program looks good. Oh, the right compares are happening? Oh, and the for loop has some fancy business going on? It must do the right!
But, look. See how the comparison that I’m printing out has nothing to do with what I’m actually doing the array? And I seem to be up to my old tricks again with just using while loops to count things. This won’t do, here is the correct version of a Bubble sort.
swap=True
while swap:
swap=False
for x in range(0,len(names)-1):
if names[x] > names[x+1]:
names[x],names[x+1]=names[x+1],names[x]
swap=True
print names
I’m now using the outer loop to keep track of whether any swaps had to happen in the previous inner loop. This ensures that the compares and swaps will keep happening until the list is ordered without trying to do fancy counting (I wonder if that’s a good rule of thumb? If you ever find yourself trying to be clever with counting you’re probably doing it wrong.).
It works and I feel good about it and I’ve written nearly 900 words about it. But I still want to sink my teeth deeper into sorting algorithms until I feel truly solid in my understanding of how to program them.