I had a rather restless evening after I got off work today. All day today at work I had things running though my head that I wanted to work on after I got home. I can’t remember a time where I’ve been so interested in my own extracurricular activities today. I had moments today where I’d be thinking about my plans for my thesis, I’d be so absorbed that my brain would short circuit. I’d realize that I didn’t remember the last few minutes except for my thoughts. Did I just use the washroom? I must have since my hands smell like soap. Did I flush the toilet?
Despite all this I stayed at work later than usual finish up some things. When I got home I couldn’t really focus on anything in particular. It was a combination of it being close to dinner time and having too many things that I could potentially work on. So I looked at funny pictures on the internet until dinner.
Joe wants to try all the food at a all the funky, super Hawaiian places around Hilo before we leave so we went down to Cafe 100 with Max. There was much gravy to be had.
When we got home I tried reading a paper about the disks of Herbig Be stars but I wasn’t feeling it tonight so I decided to try another python exercise. I’m still doing simple stuff but I had some fun with this one. The exercise was,
Given an array of names, print out a random pairing of names using every name exactly once. Handle the case where there is an odd number of names in the array.
I was pleased with how mindful I was about the things I’ve been learning. The algorithm itself came easily from thinking about what I would do if I was asked to do this with names on notecards. First, I wrote the program just handling even arrays and added the code that handles odd arrays after I already had that working. It’s pretty simple to tell that this was the case,
import random as r
names=["Alexa","Joe","Petra","Inger","Walder","Ricardo","Max"]
if len(names)%2 == 0:
while len(names) > 0:
i=r.randint(0,len(names)-1)
first_name=names[i]
del names[i]
x=r.randint(0,len(names)-1)
second_name=names[x]
del names[x]
print first_name, second_name
else:
while len(names) > 1:
i=r.randint(0,len(names)-1)
first_name=names[i]
del names[i]
x=r.randint(0,len(names)-1)
second_name=names[x]
del names[x]
print first_name, second_name
else:
print names[0]
It works though which is nice but I knew I could make a less bulky version of it. Which turns out to be,
while len(names) > 1:
i=r.randint(0,len(names)-1)
first_name=names[i]
del names[i]
x=r.randint(0,len(names)-1)
second_name=names[x]
del names[x]
print first_name, second_name
if len(names) > 0:
print names[0]
I was interested in objectively comparing these programs. There are three ways to measure the goodness of an algorithm:
1.) Correctness
2.) Size
3.) Speed
Well, they are both correct and it’s obvious who wins out over size but does the size of either program indicate anything about their corresponding speeds? To answer this question I’m going to start by saying that,
Number of Steps = Speed
Let’s start with the concise version. There are eight steps in each ‘while-loop’ and for the even case the ‘while-loop’ will run n/2 times, which we need to multiply by 8 since there are 7 steps in the loop and the comparison needs to happen. To account for the ‘if-statement’ we need to add 1 in the even case, since the comparison happens every time, and 2 in the odd when the statement is actually executed. So,
Concise Version:
Even:

Odd:

When I measured the same way for the original version I found out (surprise!) that it has the same speed as the the concise version. It’s trivial to show.
For the even case of the original version. The ‘if-statement’ runs every time the program is ran and the ‘while-loop’ is the exact same as the concise. So,
Original Version:
Even:

For the odd case it’s the ‘if-statement’ + the ‘while-loop’ + the ‘else’ thus,
Original Version:
Odd:
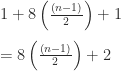
Frankly, I was more than a little surprised when I came up with this result. I was expecting the longer version to be much slower but such is life.
